When Google decided to update its official documents in June 2022, SEO practitioners and specialists started worrying about a particular piece of content that’s been added to the Googlebot crawl limit. Stated within Googlebot’s official Google documentation is the following statement:
“Googlebot can crawl the first 15MB of an HTML or support text-based file. Any resources referenced in the HTML such as images, videos, CSS, and JavaScript are fetched separately. After the first 15MB of the file, Googlebot stops crawling and only considers the first 15MB of the file for indexing. The file size limit is applied to the uncompressed data…”
Source: Googlebot
What is Googlebot?
Googlebot is the official generic name for Google’s website crawler. It’s currently responsible for gathering information from your website for SEO assessment. It provides essential information to Google on whether to index a web page or not.
Googlebot is separated into two types- Googlebot Desktop and Googlebot Smartphone. As the name suggests, these two work hand-in-hand in determining whether Google should index a website under Desktop and Mobile platforms.
So how does the 15MB Googlebot crawl limit factor into all these?
Boundaries of the 15MB Crawl Limit
The 15MB crawl limit is the standard limit set for both Googlebot Desktop and Smartphone. Being applied only to the text encoded within the HTML file or the supported text-based file of the web page.
This translates to the Googlebot crawl limit setting its boundaries within the text in your HTML file. The same texts can be found whenever one inspects the page source of a web page.

But what does this mean for the images, videos, CSS, and JavaScript resources being utilized within the HTML file? Consider the quoted text below,
“…resources referenced in HTML such as images, videos, CSS, and JavaScript are fetched separately…”
This statement simply means that the 15MB crawl limit for Googlebot doesn’t take into account the file sizes of resources being referenced in an HTML file. For example, when an image is apparent on a web page, it is usually defined by a line of code.

Whenever an image is defined through a URL- this DOES NOT account for the 15MB crawl limit. This is because the image is “referenced” from a different URL rather than being “encoded” within the HTML file itself.
The difference between Referencing and Encoding
Referencing a media or resource within an HTML file means it is only called or accessed from a different URL outside of your web page. Like a person placing an object in his/her bag instead of carrying it. This way, it’s easier to store and access the object while retaining free movement. When something is “encoded”, this translates to placing a file purely onto another. A person that prefers to carry an object around that limits his/her movement in the process.
There are currently no means of encoding a media file like an image or a video into your HTML file. But on the other hand, it’s possible to encode CSS and JavaScript codes into an HTML file.
What does this imply?
Including these codes into your HTML file contributes to additional lines of code. And extra lines of code allow your HTML file to reach the 15MB Googlebot crawl limit.
The Truth About the 15MB Googlebot Crawl Limit
It is a fact that a web page builder will almost always NEVER reach the 15MB Googlebot crawl limit that is set for indexing an HTML file. In a tweet by John Mueller, a search advocate at Google; Reaching the 15MB in your HTML file is equivalent to roughly 16 novels of which the manuscript is transferred to an HTML file.
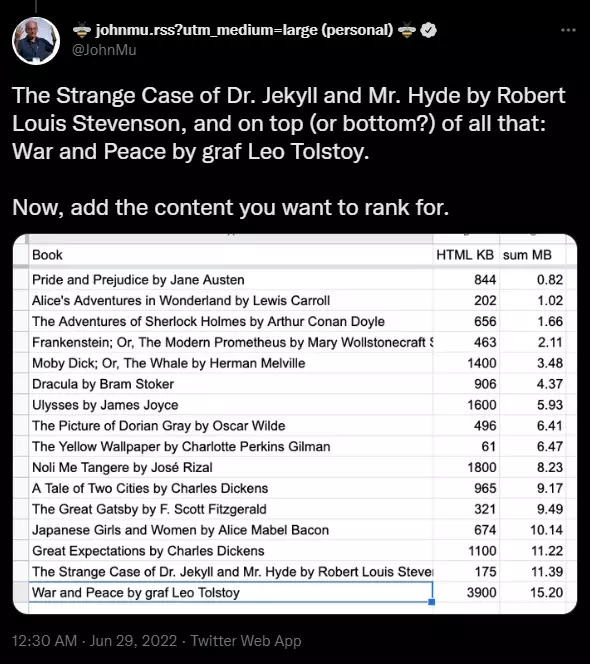
Source: Twitter
From a developer’s perspective, it’s considered an absurd amount of lines of code to place in your HTML. There will always be efficient means of building a web page, especially with site speed being considered a huge factor in website ranking. If one is curious about testing how big an HTML file is for a web page, consider using the tool DebugBear’s HTML Size Analyzer.
Googlebot’s 15MB crawl limit and Site speed
Being unable to reach the 15MB Googlebot crawl limit shouldn’t be an excuse to ignore site speed optimizations for a website. Google considers user experience as one of the biggest factors affecting website rank. This involves how fast can a web browser load a web page’s resources and elements.
The crawl limit is meant to serve as a guide for indexing and does not guarantee rank. The media and resources file not being factored into the crawl limit is not an excuse to ignore the resources a web browser loads.
Site speed should always be considered when referencing media or resources on your website.
Learn more about Site Speed Optimization here.
Key Takeaway
The newly included statement in Googlebot’s official documentation about the Googlebot 15MB crawl limit should not intimidate SEO practitioners and specialists. It should instead serve as a reminder to keep in mind how an SEO-friendly web page should be built.
Even with the recent Google Algorithms rewarding a content-based SEO strategy, it’s almost impossible to reach the 15MB crawl limit for a single web page. User experience, site speed, and continuous publication of unique content are still the priority in creating a well-optimized website.
If you want to learn more about creating a well-optimized and SEO-friendly website, check out Learn SEO: The Complete Guide for Beginners!